This post is a continuation from the last post of understanding normalization in data modeling using PowerPivot. As usual, we will be using the AdventureWorks companion material from the Ferrari book. Let us get started.
SQL Querying in PowerPivot
In the previous post I demonstrated how to denormalize a table in PowerPivot by creating calculated columns using the RELATED command. The RELATED command is an easy tool to understand denormalization. However, with SQL queries we can normalize with ease in a large database. Here we will query in SQL the necessary columns and tables to denormalize a data model. The denormalization process will be shifted outside of PowerPivot versus the previous method of denormalizing within PowerPivot using the RELATED command.
A SQL query is a statement written in SQL language used in many modern relational databases. PowerPivot has a built-in SQL query designer, of which we will discuss further.
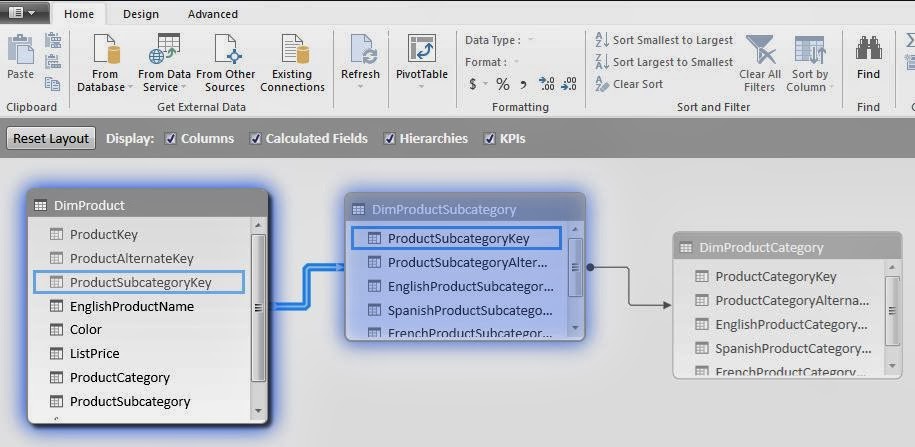
Begin by adding AdventureWorks data from SQL Server. In the Home tab of PowerPivot, click from Database and From SQL Server option.
 |
| Fig. 1: Add External Data from SQL Server in PowerPivot |
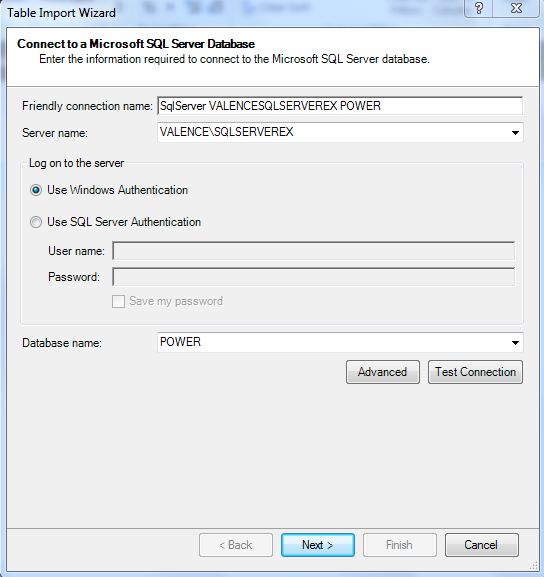 |
| Fig. 2: Connecting to SQL Server Database |
 |
| Fig. 3: Use Query Method |
SELECT
DimProduct.ProductKey
,DimProductCategory.EnglishProductCategoryName
,DimProductSubcategory.EnglishProductSubcategoryName
FROM
DimProductSubcategory
INNER JOIN DimProductCategory
ON DimProductSubcategory.ProductCategoryKey = DimProductCategory.ProductCategoryKey
INNER JOIN DimProduct
ON DimProductSubcategory.ProductSubcategoryKey = DimProduct.ProductSubcategoryKey
But for now, click the Design button as show below in Figure 4 to use the SQL query designer.
 |
| Fig. 4: Select PowerPivot Query Designer |
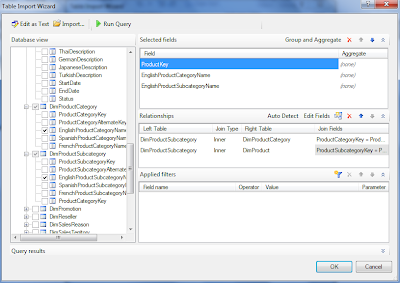 |
| Fig. 5: SQL Query Designer |
 |
| Fig. 6: SQL Query Statement from SQL Query Designer |
 |
| Fig. 7: Query Table |
Thanks for reading,
Wayne