# Twitter API Changed #
Hello Readers,
Happy 2014!
 As a micro-blogging site, Twitter has a wealth of text data to analyze. However, the text data is not in a usable form initially. So it requires extraction from the Twitter API, transformation into a document-matrix, and finally we can perform word associations or counts. Lastly, we can cluster words and tweets into groups to discover the group composition of the words and tweets. We will begin to cover these topics one by one in the Text Mining Series. Read Text Mining 2 here.
As a micro-blogging site, Twitter has a wealth of text data to analyze. However, the text data is not in a usable form initially. So it requires extraction from the Twitter API, transformation into a document-matrix, and finally we can perform word associations or counts. Lastly, we can cluster words and tweets into groups to discover the group composition of the words and tweets. We will begin to cover these topics one by one in the Text Mining Series. Read Text Mining 2 here.A few posts ago we discussed accessing the Twitter API to mine trending data in Python. Today we will discuss Twitter text retrieval in R. Note that readers will require a Twitter account to access the Twitter API.
Let us begin!
Accessing Twitter
To mine Twitter data, we first need to retrieve the text data from the Twitter API. The package twitteR will allow us access Twitter feeds. A large portion of text data come in the form of tweets. We will choose last 200 tweets from the @nbastats handle to analyze, which features daily basketball statistics. Here is what the Twitter page looks like:
 |
| @nbastats Page |
The tweets by users are located on the bottom right hand corner of the page. To access the Tweets from other applications, we need a user account to create an application in the developer's page. This way we obtain the proper credentials to access the Twitter API through the twitteR package in R.
In the application page, we will have the OAuth keys which are unique to the application. They will allow applications to authenticate with the Twitter API and access the tweets. Keep the keys secret!
 |
| OAuth Keys |
Now that we have the keys, start R and load the twitteR package (library(twitteR)). Configure the RCurl options as shown below. The cacert.pem certificate file is required and can be downloaded here to the local working directory in R.
 |
| RCurl Options |
Then assign the consumer key and consumer secret key to those variables.
SEE UPDATE BELOW- TWITTER API CHANGED.
 |
| Keys and the getTwitterOAuth() Function |
In the getTwitterOAuth() function, provide the consumer key and the consumer secret key. It will direct us to the Twitter API website with a link and once we click Accept, we are given the verification code.
And once we provide the PIN code, we are given the Access tokens and a verification of the completed handshake.
 |
| Handshake Completed |
Now that we are verified and connected, let us start querying tweets!
API Access Update:
Instead of using the getTwitterOauth() function, we need to setup manually an OAuth object. Make sure the internet addresses begin with https://, and you have loaded the twitteR, ROAuth, and XML packages. The RCurlOptions need to be set as well.

After you initiate the handshake() function, you will be prompted to enter a code from the dev.twitter page into R. To verify the completion of the handshake, simply call cred.
Retrieving Tweets
One thing to note: the cacert.pem specification is required for every tweet query. So when we use the userTimeline() function, we need to assign the certificate to the cainfo argument, in addition to the user handle and number of tweets. Again, we will be using @nbastats. We will try to retrieve up to 200 tweets from that timeline. Here is what the tweets look like at the beginning of the new year:
 |
| Tweets from @nbastats |
We can save the nba.tweets file to preserve the data and be able to work with it later. Each tweet is a single line, and the number of tweets are quite burdensome to work with. We can access specific tweets by using brackets "[ ]". Let us access tweets 20 to 25.
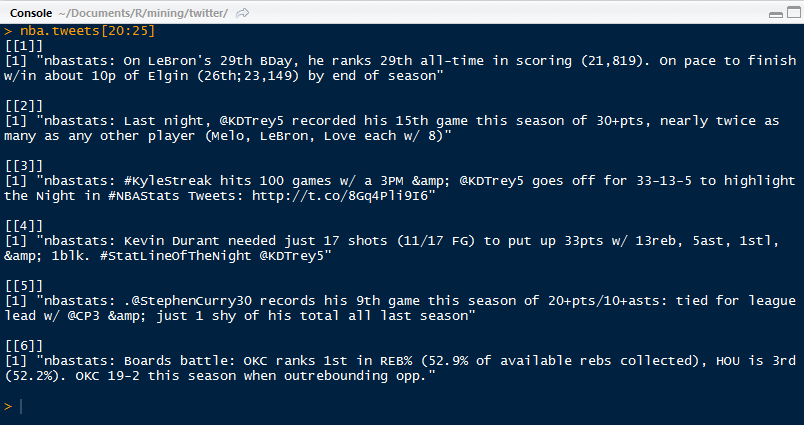 |
| Selected Tweets Numbers 20 to 25 |
Formatting Tweets
We can use text wrapping to make the text output more readable. Create a function that will take arguments for the tweet object name, lower tweet number, and higher tweet number. My version looks something like this:
 |
| Tweet Printing Function |
Observe that there are 3 arguments and a for loop in the function. I start the output with double brackets indicating the number tweet. We saw before in the output, that even the tweets were from 20 to 25, the brackets still showed from 1 to 6 given the order they were printed. We would like the actual tweet number to be shown.
The strwrap() function wraps a string by breaking lines at word boundaries. The specification was 73 columns in width. The output for the initialized function is shown below for tweets 20 to 25 from nba.tweets. Note how the tweet numbers are printed in brackets and the nbastats prefix was removed from each tweet.
 |
| Printed Tweets from @nbastats, Numbers 20 to 25 |
Now we can explore other Twitter users and what they tweet. Next we will transform the text and create a corpus to build a document-matrix. So stay tuned!
Thanks for reading and have a great New Year,
Wayne
@beyondvalence
Thanks for this...was trying to access twitter with R but everytime there was one or the other issue...very good tutorial
ReplyDeleteThanks Ashutosh! Glad this post helped!
ReplyDeleteThat is very interesting; you are a very skilled blogger. I have shared your website in my social networks! A very nice guide. I will definitely follow these tips. Thank you for sharing such detailed article.
ReplyDeleteData Science Online Training|
R Programming Online Training|
Hadoop Online Training
Well Said, you have furnished the right information that will be useful to anyone at all time. Thanks for sharing your Ideas.
ReplyDeleteHadoop Training in Marathahalli|
Hadoop Training in Bangalore|
Data science training in Marathahalli|
Data science training in Bangalore|