Hello Readers,
Today we will model data with neural networks in R. We will explore the package neuralnet, and a familiar dataset, iris. This post will cover neural networks in R, while future posts will cover the computational model behind the neurons and modeling other data sets with neural networks. Predicting handwritten digits (MNIST) with multi-layer perceptrons is covered in this post.
 |
| The Trained Neural Network Nodes and Weights |
So far in this blog we have covered various types of regression (ordinary, robust, partial least squares, logistic) and classification (k-means, hierarchical, random forest) analysis. We turn to neural networks for a new paradigm inspired by imitating biological neurons and their networks. The neurons are simplified as nodes to an input layer, a hidden layer(s), and output nodes.
Let us start R and begin modeling iris data using a neural network.
Organizing the Input Data
First, we require the nnet and neuralnet packages to be loaded in R. Next, we print the first six rows of iris, to familiarize ourselves with the structure. Iris is composed of 5 columns with the first 4 being independent variables and the last being our target variable- the species.
 |
| Libraries and Iris |
After determining the species variable as the one we want to predict, we can go ahead and create our data subset. Additionally, we notice that there are 3 species grouped together in 50 rows each. Therefore, to create our targets, or class indicators, we can using the repeat function, rep(), three times to generate indicators for setosa, versicolor, and virginica species.
 |
| Subset and Target Indicators |
Naturally, we will split the data into a training portion and a testing portion to evaluate how well the neural net model fits training data and predicts new data. Below, we generate 3 sets of 25 sample indexes from the 3 species groups of 50 rows- essentially half the data with stratified sampling. Afterwards, we column bind the target indicators with the training indexes to the iris data set we created, again only selecting by training indexes. A sample of 10 random rows are printed below, and note how the species indicator includes a 1 denoting the species type:
 |
| Iris Training Data |
Training the Neural Network
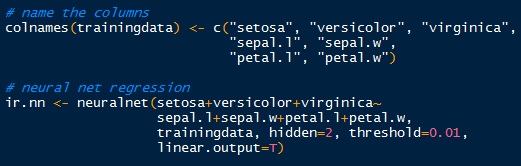
Now that we have the targets and inputs in our training data we can run the neural network. Just to make sure, verify the column names in the training data for accurate model specification, modifying them as appropriate.
Using the neuralnet() function, we can specify the model starting with the target indicators: setosa+veriscolor+virginica~. Those three outputs are separated by a hidden layer with 2 nodes (hidden=2), which are fed data from the input nodes: sepal.l+sepal.w+petal.l+petal.w. The threshold is set by default at 0.01, so when the derivative of the sum of squares error-like term with respect to the weights drops below 0.01, the process stops (so weights are optimal).
 |
| Neuralnet Training |
Plotting the Neural Network
Now that we have run the neural network, what does it look like? We can plot the nodes and weights for a specific covariate like so:
 |
| Visualizing the Neural Network |
Hopefully I am not the only one who thinks the plot is visually appealing. Towards the bottom of the plot, an Error of 0.0544 is displayed along with the number of steps, 12122. This Error number is similar to the sum of squares.
 |
| Iris Neural Network Nodes |
By default, the gwplot() plots the first covariate response with the first output, or target indicator. So below, we see species setosa with sepal length weights. The target indicator and covariate can be changed from default.

Validation with Test Data
How did the neural network model the iris training data? We can create a validation table with the target species and the predicted species, and see how they compare. The compute() function allows us to obtain the outputs for a particular data set. To see how well the model fit the training data, use compute() with the iris.nn data with training indexes. The list component $net.result from the compute object gives us the desired output from the overall neural network.
 |
| A Good Fit |
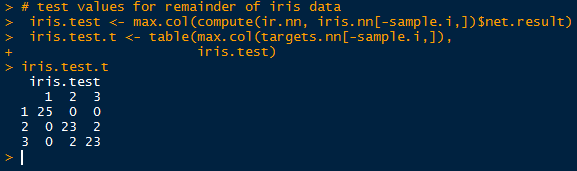
Observe in the table above that all 75 cases were predicted successfully in the model. While it may seem like a good result, over-fitting can encumber predictions with unknown data, since the model was trained on the training data. No hurrahs yet. Let us take a look at the other half of the iris data we separated earlier into the test set.
 |
| Test Results |
Simply take the inverse (-sample.i) of the sample indexes to obtain the mirrored test data set. And look, we did not achieve a perfect fit! Two in group 2 (versicolor) were predicted to belong in group 3 (virginica), and vice versa. Oh no, what happened? Well, the covariates in the training set cannot account for all known and unknown variations in the test covariates. There is likely something the neural network has not seen in the test set, so that it would mislabel the output species.
This highlights a particular problem with neural networks. Even though the network model can fit the training data superbly well, when encountering unknown data, the weights on the nodes and bias nodes are geared towards modeling the known training data, and will not reflect any patterns in the unknown data. This can be countered by using very large data sets to train the neural network, and by adjusting the threshold so that the model will not over-fit the training data.
And as a final comment, I calculated the root mean square error (RMSE) for the predicted test results and the observed results. The RMSE from this neural network for the test data is approximately 0.23.
 |
| RMSE of Test Data |
The results are not too bad, considering we only trained it with 75 cases. In the future I will post another neural network, revisiting the MNIST handwritten digits data, which we model earlier with Random Forests.
Stay tuned for more R posts!
Thanks for reading,
Wayne
@beyondvalence
Dapatkan Pasaran Bola Terbaik di Situs Agen Resmi BOLAVITA !
ReplyDeletewww.bolavita.site Agen Taruhan Bola Online yang sudah di percaya dan sudah berdiri sangat lama di dunia perrjudiian Indonesia !
Aman dan Terpercaya !
Hubungi Cs kami yang bertugas 24 jam Online :
BBM: BOLAVITA
WA: +6281377055002
Atau bisa langsung download Aplikasi Resmi BOLAVITA :
Aplikasi Playstore : Bolavita Sabung Ayam