Hello Readers,
So far we have dealt with time series (and other data) on this blog with raw R plot outputs, predicted trends, and time series decomposition. This post will take an aesthetic turn to data presentation, and transforming a graph into a graphic. A previous post turned #Crimea tweets into a word cloud.
 |
| Resulting Graphic |
We will focus on Crimea, and element palladium, Pd (atomic number 46), where the rare metal constitutes parts of catalytic converters, electronics, jewelry, dentistry, and fuel cells . Why palladium and Crimea together? Well, in late January of 2014, nearly 70,000 miners in South Africa called a strike, stopping 40% of world production of palladium. Although talks in late April appear to have solved the issues, the strikes are still on, as of this writing. With Russia producing 44% of the world's palladium supply, Russia and South African control 84% of the world's palladium production.
 |
| Catalytic Converter |
As sanctions flew back and forth due to the Ukraine Crisis, the supply of palladium from Russia was considered at risk. Pro-Russian forces entered the Crimean peninsula in February, days after Russia refused to acknowledge the Yatsenyuk Government post Ukrainian Revolution. After a majority in the referendum in Crimea voted to join Russia, the United States and EU denounced Russia as Putin signed a treaty of accession with Crimea and Sevastopol. Then several eastern cities in Ukraine came under occupation by pro-Russian forces/demonstrators, who seized government buildings.
Click here for Ukraine Crisis in Maps by The New York Times
Even with the Ukraine Agreement on April 17th, temporarily stopping hostilities between Ukraine and Russia, tensions are still rising as politicians in Kiev seek to oust militants from their eastern cities. The deputy prime minister of Ukraine, Vitaliy Yarema, said "the active phase of the anti-terrorist operation continues" after the Easter holiday (April 26-27th), despite 40,000 Russian troops massing at the Russian-Ukrainian border, conducting military drills.
The United States has responded by sending troops to Poland, Lithuania, Latvia, and Estonia, after NATO increased their presence in eastern Europe. EU and NATO countries have resorted to sending troops in response to Russian troop movement, and international sanctions on Russia had little effect on their military actions surrounding Ukraine.
While Vladimir Putin acts undeterred by the wide economic sanctions, and of top Russian officials, troop movement on both sides will only escalate. That not only endangers palladium production (the point of the post), but also risks the lives of Ukrainians and the future of eastern Europe.
Palladium Data
I obtained the palladium data from Quandl, a site that hosts data sets. The palladium data source is from John Matthey's Precious Metals Marketing. You can download the data by clicking the red download button and selecting the file type (I picked CSV).
 |
| Quandl- Palladium Prices |
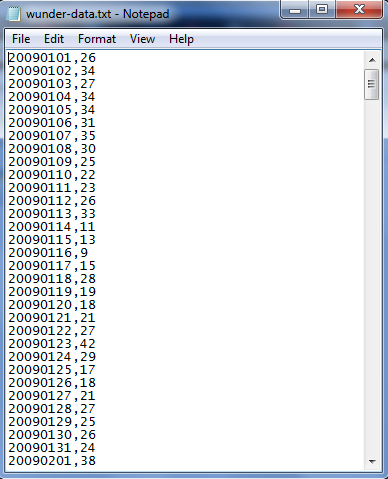
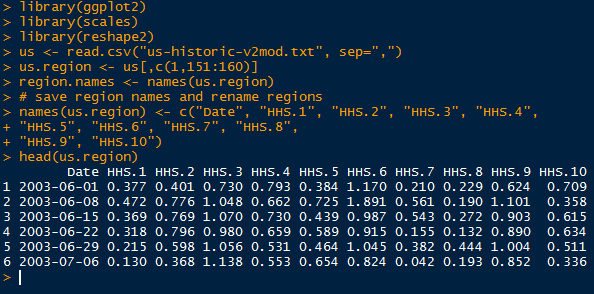
Open R, and read the CSV file with a header. Make sure your working directory is set where the data set is saved, and use the head() function to get an idea of what the data set contains.
 |
| Snapshot of Palladium Data |
We see a date column with the format of "year-month-day", and the morning and afternoon prices in Hong Kong and New York, and only the morning price from London. We need to format the date column into a date type using as.Date(). Call str() to verify the type of the date column. Looking below, the date column is now in the date format.
 |
| Date Format |
We will use the morning prices from Hong Kong ($Hong.Kong.8.30) because it has the most consistent, recent data out of the 5 price variables. For the recent date range, we aim for 2010 to present to capture the rise in palladium prices in 2011 in addition to the prices in late April 2014. After some exploring, we discover the starting index at row 1080.
 |
| Subset and Fix Value Typo |
After we create the new subset, of the values from 2010 onward for the date and morning HK values, we discover the price range is slightly odd. There is a rather low anomaly price of 72. Using which.min() we locate the low price index at 131. To verify 72 is (in)correct, we look at the other variable locations at row 131, and realize that 72 was not the likely starting price. We impute a value of 723 at row 131 based on prices from other locations.
Now we can plot the palladium price get an idea of the data trend (and to see if it matches vaguely with the plot on Quandl). Add some color, axis labels, and title to the plot.
 |
| Plotting Palladium |
We see the result below. Looks good, but this 'good' does not represent publishable material. This is simply raw R plot output.
 |
| Raw R Plot Output |
Since this post is about turning a graph into a graphic, I made a few modifications to the R plot in Adobe Illustrator. First I used the direct selection tool to delete the plot borders, and to move the title, axis labels, and create the dashed lines as enhanced tick marks. Then I utilized the type tool to add text to highlight specific events on the time series, and created a sub-title explaining the graphic.

As a result of refining the plot through Illustrator, we see an improved visual with more pertinent information about South African, Ukraine, Russia, and palladium prices. The view can observe the events from the labels, and see the rise in palladium prices in response. However, this is not mean direct causation, but logically the effect of strikes/sanctions with production control and rising scarcity/prices makes sense. We want the visualization to invoke thought, and raise questions about the mechanisms behind the palladium price fluctuations. (Hopefully we will not encounter WWIII- and Putin is not shy about brinkmanship).
Stay tuned for more R analytics posts, and keep an eye out for additional visualization posts!
Thanks for reading,
Wayne
@beyondvalence