Hello Readers,
Today we will discuss data scraping, from a website's page source in HTML. Most of the times when we analyze data, we are provided the data, or are able to find the data through an online database. When we do, the data are usually arranged in a CSV/TSV format or as a convenient database waiting to be queried. Those types of data are known as structured data, and comprise only a fraction of the data available on the web.
To retrieve unstructured data is usually a time consuming process if processed manually, since the data are not organized, or are large sections of text, such a server logs or Twitter tweets. They could even be spread over a number of web pages, for example, the maximum daily temperature in Fahrenheit for Buffalo, New York, starting from 2009. A screenshot highlighting the maximum temperature is shown below.
 |
| Weather History for Buffalo, NY |
At 26 degrees, it was a cold New Years day in Buffalo. From the drop down options we can select January second to view that day's maximum temperature. You can imagine the time required to obtain the maximum temperature for each day in 2009. However, we can automate this process and skip the copy and paste/manual entry of the temperature through a Python script. We will use Python scrape temperature data from Weather Underground's website [1- Nathan Yau Flowing Data].
HTML Source
One thing to notice is the Buffalo historical weather page URL:
http://www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html?req_city=NA&req_state=NA&req_statename=NA&MR=1
Even if we delete the URL after ".html", the page still loads. Also, we can spot the date in the URL, "/2009/1/1/". Remember this URL component, because it will be important when we automate the scraping with loops. Now we have discovered the range of URLs for daily weather in Buffalo in 2009.
http://www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html
to ->
http://www.wunderground.com/history/airport/KBUF/2009/12/31/DailyHistory.html
In order for the Python script to scrape the data from the Weather Underground sites, we need to access the page source and see how the maximum temperature is coded. In Chrome, you can right click the page to view the page source in HTML.
 |
| HTML Page Source |
Either through scrolling through the page or pressing Ctrl+F to find the text "Max Temperature", we can locate the desired temperature and the HTML tags around it. We spot the Max Temperature values enclosed by span class="wx-value" tags. Note that our target value is the third value enclosed by the span tag. The first two temperatures are the Mean Temperatures.
Python Script
We will use 2 libraries access the website and parse the HTML: urllib2 and BeautifulSoup. The first module provides standard functions for opening websites, and the second module is the crucial one. Created by Leonard Richardson, Beautiful Soup gives Python the power to navigate, search, parse, and extract parts of code we need.
After we import the two modules, we need to create the text file "wunder-data.txt" to which we will write the maximum temperatures.
 |
| Import and Open Text File |
To automate the scraping process, we use loops to cover the months and the days in each month. Keeping in mind of the different days in each month, we use if and elif statements to check February, April, June, September, and November.
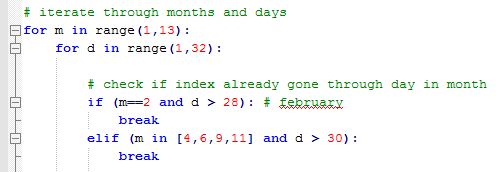 |
| Looping |
Inside the loops, we will print out the current date we are retrieving, and access the url with the current month (m) and day (d) using method urllib2.urlopen().
 |
| Print Current Date and Open Respective URL |
After we opened the page, we pass it through BeautifulSoup(), and then use the soup.findAll() method to locate the tag "class: wx-value". Then we take the third value, [2], since the python index starts at 0, and bind it to our dayTemp variable. Next we format the month and day to be 2 characters by adding a "0" if required.
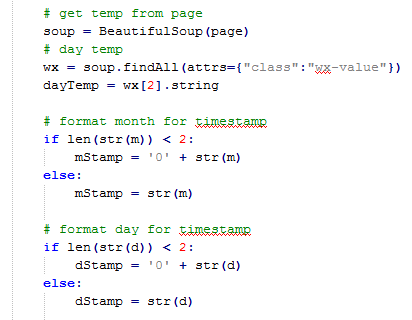 |
| Using BeautifulSoup and Date Formatting |
Now that we have the temperature in dayTemp, and proper date formatting, we create a timestamp with which we will write the dayTemp. This way, we can see the date of the retrieved maximum temperature.
 |
| Timestamp and Writing |
Outside of the loops, we close the finished text file and print out a finished indicator. Below we have the output of the wunder-data.txt file. Observe the time stamp with 8 characters (4 for year, 2 for month, and 2 for day) followed by a comma and the temperature.
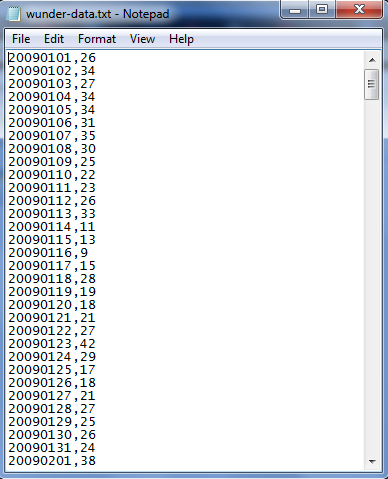 |
| File Output |
This post illustrates the basic concepts to data scraping:
1. Identifying the pattern (in URL / HTML source)
2. Iteration (script)
3. Storing the data (writing to file)
There are many other measures we could have included, such as the minimum temperature, or even a moving average of the maximum temperature in the script. The important thing is, do not let yourself be confined to using structured data in forms of CSV, TSV, or Excel files! Unstructured data are out there in large quantities, and it is up to you to retrieve, and clean them to be fit for analysis.
Thanks for reading,
Wayne
@beyondvalnence
Thx
ReplyDeletevery helpful!
its very nice article. thanks for sharing such great article hope keep sharing such kind of article Web data scraper
ReplyDeleteDapatkan Pasaran Bola Terbaik di Situs Agen Resmi BOLAVITA !
ReplyDeletewww.bolavita.site Agen Taruhan Bola Online yang sudah di percaya dan sudah berdiri sangat lama di dunia perrjudiian Indonesia !
Aman dan Terpercaya !
Hubungi Cs kami yang bertugas 24 jam Online :
BBM: BOLAVITA
WA: +6281377055002
Atau bisa langsung download Aplikasi Resmi BOLAVITA :
Aplikasi Playstore : Bolavita Sabung Ayam
Download free MS PowerPoint templates , themes and PowerPoint backgrounds for your presentations. Get immediately best Microsoft PPT templates on TemplateMonster.
ReplyDeleteI am really very happy to visit your blog. Directly I am found which I truly need. please visit our website for more information about Web Scraping Service Providers in USA
ReplyDelete