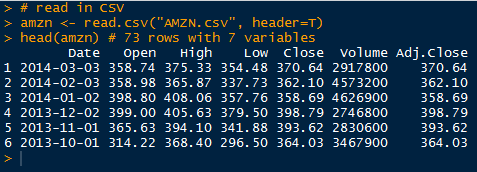
Hello Readers,

You might have heard about Google Fiber, where you browse and stream in the world of blindingly fast internet speed. How fast exactly? 100 times as fast, at 1,000 mbits/s (megabits per second). The rest of us in the United States have to trudge along with an average of 20 mbits/s while downloading, where actual speeds lag in around ~8 mbits/s. Such is the power of the clauses like "speeds up to __".
Unfortunately Google Fiber is only available in select cities (Kansas City, Austin TX, and Provo UT). So if you do not live there or any of these places, you probably will still be streaming Netflix and YouTube at average speed. Bummer. Here is a YouTube video demonstrating Google fiber speeds.
Internationally, the United States is beginning to lag behind other countries in broadband speed (download and upload). Take South Korea for instance. Entering into this millennium, South Korea has built significant networking infrastructure, and South Korean brands such as Samsung and LG have permeated the world electronic stage with high quality products. What Japan accomplished with innovating cars, right now South Korea is doing with electronics. And you guessed it, they also upgraded their broadband infrastructure as their economy focused on high tech in the 1990s. Their download and upload speeds are more than twice that of US counterparts (we generate the below plot in the post).
 |
| S.K. Download Speeds in 2009 > U.S. Download Speeds in 2014 |
Also, two of South Korea's largest mobile carriers, SK Telecom and LG Uplus Corp, are rolling out a new LTE broadband network in 2014 at 300 megabits per second. Compare that speed to 8 megabits per second here in the U.S. There are many factors involved to make this possible in South Korea, such as high population density of 1,200 people per square mile, and government regulation to bolster competition among service providers. In the U.S., providers have their own closed-network system, so by switching to/from Comcast or Verizon, you would have to install new cables. This infrastructure dilemma acts as a cost barrier for new companies looking to enter into the broadband market.
Enough of the Fiber talk. We are here to discuss average internet broadband speeds for average people. And just because our internet is slower here in the U.S., does not mean that it does not work. Lucky us, there is open data available at Data Market. Let us start R and crunch the data!
Broadband Data
Start here for the exact data set from Data Market. This data is provided by Ookla, an internet metrics company. You most likely have used their speed test utility to measure your internet speed. The data set has many countries from which to select the download and upload speeds including the World average speed in kilobits per second. Make sure the United States and South Korea variables are selected with download and upload speeds before clicking the Export tab and downloading the CSV file.
 |
| Data Market- Broadband Speeds CSV |
Now that we have downloaded the CSV file, we can import it into R:
 |
| Reading in the Broadband CSV Data |
Note the columns and their data. There are 5 columns designating the year-month, South Korean download speed, South Korean upload speed, U.S. download speed, and U.S. upload speed, all in kilobits per second. We will be splitting the the last four into individual time series and appending them to a list due to their different lengths (South Korea has less data points).
Remember to remove the last row in all columns, since it contains just a descriptor of the variables and null values. The creation will result in 4 time series: download and upload speeds for the U.S., and download and upload speeds for South Korea. Take notice that we divide each time series by 1000 to obtain megabits per second from kilobits per second.
 |
| Creating Time Series Data.frames and a List Class |
The bb (broadband) list allows us to use a shorter input method, and aggregates all the time series into one list object. We could not create a data.frame with all four time series because the South Korea and U.S. series have different number of data points. South Korea data start at September 2008, whereas U.S. data start in January 2008. The bb list contents are shown below:
 |
| Time Series in List Contents |
Plotting Broadband Speeds
Since we have two countries with two time series each, we will prudently use color coding for visual purposes. First we plot the download speed for South Korea in dark green using plot(), making sure to specify custom y and x axis to fit the data for U.S. as well. Next we add the remaining three time series with lines() with upload speed for South Korea in green, and the download and upload speeds for the U.S. in dark orange and orange, respectively.
 |
| Broadband Time Series Plot Code |
Lastly we add a legend with the label and colors to yield our plot below:
 |
| Broadband Plot |
And look at those colors! We can observe the South Korean green lines after mid 2011 are much higher than the orange yellow lines of the U.S. broadband speeds. In fact, we can see that download speeds in South Korea in 2009 were higher than our download speeds in the U.S. now in 2014!
The Future of Broadband?
Of course we would want to know the forecasts of the time series. With our current technologies, how fast would our broadband speeds be in 2 years? Specifically, we want to ballpark our download speeds in the U.S. compared to South Korea. In previous time series posts, we used regression and ARIMA methods to forecast future values for wheat production and Amazon stock prices respectively. To create a prediction, or forecast, we will turn to exponential smoothing for these broadband data.
Exponential smoothing estimates the next time series value using the weighted sums of the past observations. Naturally we want to weight more recent observations more than previous observations. We can use 'a' to set the weight 'lamba':
lambda = a(1-a)^i, where 0 < a < 1
such that xt = a*xt + a(1-a)*xt-1 + a(1-a)^2 * xt-2 + ...
This procedure is called the Holt-Winters procedure, which in R manifests as the HoltWinters() function. This function includes two other smoothing parameters B for trend, and gamma for seasonal variation. In our case, we would simply specify the data and R will use determine the parameters by minimizing the mean squared prediction error, one step at a time.
Let us consider the exponential smoothing over the download speeds of the U.S. and South Korea. The U.S. output is shown below:
 |
| Holt-Winters Exponential Smoothing |
We can see the HoltWinters() function determined the three parameters, alpha, beta, and gamma. Next we overlay the fitted values from the HoltWinters() function to the real download speed time series to visualize how they approximate the actual values. The plot code is shown below, with different line colors for visual contrast:
 |
| Holt-Winters Plot Code |
The resulting plot is displayed below:

Okay, the Holt-Winters procedure did a good job of approximating the the observed time series values, as seen by the red and yellow lines above for estimated U.S. and South Korea download speeds.
Now that we have confirmed the model, we will go ahead and predict the next 2 years of broadband download speeds using the predict() function passing through the Holt-Winters objects. The predicted values are shown below:
 |
| Predicted 2 Years Values from Holt-Winters |
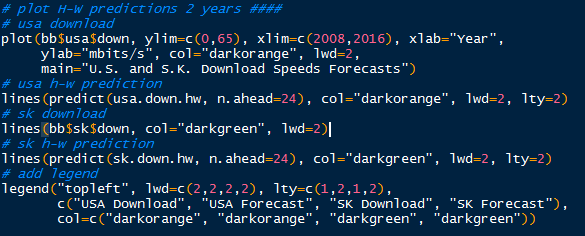 |
| Plotting Predicted 2 Year Values |
The prediction plot is depicted below.

Observe the U.S. download speeds with 2 year forecast in orange, and the South Korea download speeds in green. Note the forecasts as dashed lines. We see that the exponential smoothing predicted increases in U.S. and South Korea download speeds, with South Korea download speeds over 60 mbits/s and 28 mbits/s in the U.S.
In case you were curious, I also predicted the future upload speeds 2 years ahead to 2016 as well. U.S. upload speeds predicted by the Holt-Winters procedure barely exceeds 5 mbits/s, while upload speeds in South Korea rises above 55 mbits/s. Both predicted download and upload speeds in South Korea in 2016 are well beyond the broadband speeds in the U.S. The upload speeds plot is shown below:

Hopefully this post gives you guys a better idea of the state of broadband speeds now and after here in the U.S., and what could be possible, namely in South Korea. It is humbling to reiterate again that download speeds in the U.S. now in 2014 have not yet exceeded South Korean download speeds back in 2009.
We would have to keep an eye out on this Comcast merger with Time Warner Cable. Merged, Comcast would control 40% of broadband market and have 30 million TV subscribers. And if New York allows it, I suspect lukewarm increases in broadband speeds, if at all. Google Fiber, where are you?
Stay tuned for more R posts!
Thanks for reading,
Wayne
@beyondvalence