Hello Readers,

In our last post in the Text Mining Series, we talked about converting a Titter tweet list object into a text corpus- a collection of text documents, and we transformed the tweet text to prepare it for analysis.
However, the tweets corpus is not quite done. We are going to stem the tweets and build a document matrix which will enable us to perform frequent term searches and word associations. So now we will continue where we left off from Text Mining 2. Read Text Mining 4 here.
Start R and let us begin!
Stemming Text
Here we have one more step before we start with the basics of counting word frequencies. Since we are looking at the @nbastats handle, consider the word score. It can exist in many other forms, such as scoring, scored, or scores and so on. When we want to count the number of score terms, we would like all the variations to be counted.
So stemming score and other words will allow us to count different variations as the same term. How is this possible? Stemming will truncate words to their radical form so that score, scoring, scored, or scores will turn into 'scor'. Think of stemming as linguistic normalization. That way different spelling occurrences will appear as the same term, and will be counted towards the term frequency.
In R, load the SnowballC package, along with twitteR, and tm. The SnowballC package will allow us to stem our text of tweets. The tweets corpus data was created in the previous post.
 |
| Load Packages and Tweets Corpus |
After creating a copy of the tweets corpus for a reference prior to the stemming changes, we can proceed with the stemming. With the tm_map() function, use the stemDocument transformation. Inspect the documents in the text corpus with the inspect() function.
 |
| Stemming and Inspecting the Document |
Check the pre-stemmed tweet:
 |
| Copy of Tweet 4 |
See how the 'leaders' and 'entering' in the copy corpus were stemmed to 'leader' and 'enter' in the transformed corpus. Like the function we created with string wrapping for printing tweets from the tweets list in Retrieving Twitter Tweets. Here is the one for printing tweets from a stemmed text corpus:
 |
| Print Tweets from Corpus Function |
The output for tweets 4 through 9 are shown below.
 |
| Tweet Corpus Documents 4 to 9 |
Next instead of stemming, we will have to implement stem completion.
Stem Completion
We complete the stems with the objective to reverse the stemming process so that the text looks more 'normal' and readable. By passing the tm_map() the stemCompletion() function, we can complete the stems of the documents in tweets.corpus, with the tweets.corpus.copy as the dictionary. The default option is set to complete the match with the highest frequency term.
 |
| Stem Completion Function |
Then we can call the function to print out the tweets for 4 through 9 again, and the output for before and after stem completion are stacked below:
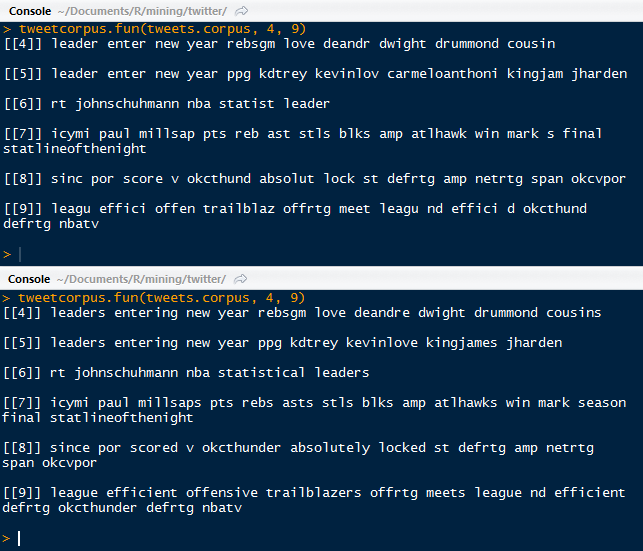 |
| Text Corpus Stem Completion Comparison |
There are several things to note. Starting at the beginning of tweet 4, we can see that 'leader' was replaced with 'leaders', 'enter' with 'entering', 'deandr' with 'deandre' (DeAndre Jordan the center for the Los Angeles Clippers), 'cousin' with 'cousins' (DeMarcus Cousins, the center for the Sacramento Kings).
However, there are some major differences, such as 'carmeloanthoni' being completely omitted after the stem completion (sorry Melo)- although 'kingjam' was replaced with 'kingjames' (congrats LeBron James). 'statist' was completed to 'statistical'. 'millsap' was incorrectly completed to 'millsaps' (correct as Millsap- sorry Paul). Some shorthand was completed as well- 'reb' was completed to 'rebs' for rebounds. Looking at 'effici' it was completed to 'efficient'.
From the last tweet (9), we see that 'd' was completed to 'defrtg' (short for defensive rating), although that it was just a regular 'd' to begin with. The 'okcthund' was completed to a more familiar 'okcthunder' (Oklahoma City Thunder).
So not all completions did a phenomenal job. That is to be expected when we use the default of completing the stemmed matches with the highest frequency in the dictionary, the copy of the corpus.
Building a Term-Document Matrix
Now that we have stemmed and completed our text corpus, we can proceed to build a term-document matrix. Load the tm and twitteR packages, and continue using the stem completed corpus.
 |
| Loading Packages and Text Corpus |
In a term document matrix, the terms are the rows and the documents are in the columns. We can also create a document term matrix, and that would simply be the transpose of the term document matrix- the documents are represented by the rows and the terms by the columns. With the TermDocumentMatrix() function, we can create the term document matrix from our tweet text corpus. See in the output below, that there are 606 terms and 186 documents (tweets).
 |
| Using the TermDocumentMatrix() Function |
There is also a 98% sparsity, which means that 98% of the entries are 0, so the row term does not exist in a particular document column. We can display the terms by calling the term dimension names. It is quite extensive a only a fraction of the 606 terms is show below.
 |
| Terms |
Observe some (basketball) recognizable terms such as "careerhigh", " blakegriffin", or "chicagobulls"- but which term had the most occurrences in all the tweet documents? We can figure that out using the apply() function and summing across the rows of the term document.
 |
| Most Occurring Term: games, 79 times |
We can also tweak the function to show the terms with more than 20 occurrences by passing it through the which() function.
 |
| Terms With 20 + Occurrences |
See that some of the top terms are "asts" assists, "fg" field goals, "games", "okcthunder" Oklahoma City Thunder, and "ppg" points per game among the various terms.
Let us visualize the term document matrix for specific terms and documents. We can assign the occurrences of the most frequent term, "games" in an index, and the following few terms for specific tweet documents. Again, we will use the inspect() function to gain snippets of the term document matrix.
 |
| Term Frequencies in Tweet Documents 60 to 70 |
Note that the sparsity is 87%, so like the rest of the matrix, this sub-matrix is mostly comprised of zero entries. Looking at the frequent "games" term, we do see that particular term appearing in the documents quite often, and even twice in tweet document 64. The abbreviation "gms" is also shown as well.
At the beginning we started with a corpus of tweet text, and we stemmed it, completed the stems, and converted it into a term document matrix. From the TD matrix we were able to count the frequencies of the terms in each document, bringing the data a final step closer to analysis-ready.
In the next post we will begin to analyze the text data, and we shall demonstrate term frequencies, term associations, and word clouds. Stay tuned!
Thanks for reading,
Wayne
@beyondvalence
Hey, your article is amazing! I have been working on the same as my summer project, I did it upto the text cleaning part but when i go for stem completion then i get an error. I luked for a solution in google and i found out that the current version of the " tm " package does not support the stemCompletion command for the corpus!! my work is terribly stuck there. It would be very kind of you to help me with this if you can.
ReplyDeleteGood Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging…
ReplyDeleteData Science Online Training|
R Programming Online Training|
Hadoop Online Training
Hats off to your presence of mind..I really enjoyed reading your blog. I really appreciate your information which you shared with us.
ReplyDeleteHadoop Training in Marathahalli|
Hadoop Training in Bangalore|
Data science training in Marathahalli|
Data science training in Bangalore|
Good Post Admin!
ReplyDeleteBe project center in chennai | Ms project center in chennai
Thank you for this useful blog!
ReplyDeleteVlsi training in chennai| Matlab training in chennai
I am very impressed with the article I have just read,so nice....
ReplyDeleteDj in Coimbatore
Thank you so much for this good information!
ReplyDeleteWedding planners in Coimbatore
ciri ayam bangkok yang super
ReplyDeleteblockchain makes all the online transactions more secure blockchain training in hyderabad
ReplyDelete