This post will explore calculated columns and fields in PowerPivot, using the sample database from the Ferrari PowerPivot book. We will continue to use the PivotTable and data model from the previous post.
Creating a Calculated Column
From the previous post, we created a PivotTable depicting the SalesAmount by Color, and CalendarYear.
 |
| Fig. 1: SalesAmount by Color by CalendarYear PivotTable |
To understand the profitability from the sales, we account at least for the product cost as well. So the TotalProductCost column needs to be added from the FactInternetSales table.
 |
| Fig. 2: SalesAmount with TotalProductCost PivotTable |
The TotalProductCost column was added beside each SalesAmount column in the PivotTable shown in Figure 2. For certain reports arranging columns side by side is better, but for readability for this report, we could like to position the fields in rows resembling the subtraction to obtain the profit data. So drag the Σ Values to the Rows area, as in Figure 3.
 |
| Fig. 3: Dragging the Σ Values to Rows Area |
The PivotTable is now easier to read and set up for the calculated column.
 |
| Fig. 4: Revised SalesAmount and TotalProductCost PivotTable |
The FactInternetSales table has no gross margin column, which is the difference between SalesAmount and TotalProductCost. So we will add a column called GrossMargin in PowerPivot as a calculated column, which extends the content of a table and is stored in the data model. First, navigate to the FactInternetSales table in the PowerPivot window. In the Design tab, click the Add button which will add a new column to the end of the table.
 |
| Fig. 5: Add Column Button |
Now we use simple DAX language to calculate the GrossMargin column. Though DAX syntax can be more intensive, the formula is very straight forward. Type in:
= FactInternetSales[SalesAmount] - FactInternetSales[TotalProductCost]
as shown in the Figure 6 below. It subtracts the TotalProductCost from the SalesAmount for the GrossMargin column, and it is now in the data model. The column can be renamed by right-clicking the column header and selecting Rename Column.
 |
| Fig. 6: GrossMargin Formula |
Let us add the GrossMargin column to the Values area in the PivotTable. We can find it in the FactInternetSales table where we created it in PowerPivot. It would go in the Values area.
 |
| Fig. 7: PivotTable with GrossMargin |
We can use DAX to solve more complex calculations, which we will explore in future posts. However with this simple DAX formula we have created a calculated column and displayed it on the PivotTable.
Creating a Calculated Field
A calculated field, also known as measures, are computed at an aggregate level, compared to calculated columns, which are computed for every row. For example, let us compute the gross margin as a percentage of the total sales amount.
Add a new column in PowerPivot to the FactInternetSales table which calculates the gross margin percentage. We might enter this as the formula for GrossMarginPct:
=FactInternetSales[GrossMargin] / FactInternetSales[SalesAmount]
 |
| Fig. 8: Formula for GrossMarginPct |
Then display the resulting GrossMarginPct in the PivotTable under the Values area.
 |
| Fig. 9: PivotTable Including GrossMarginPct |
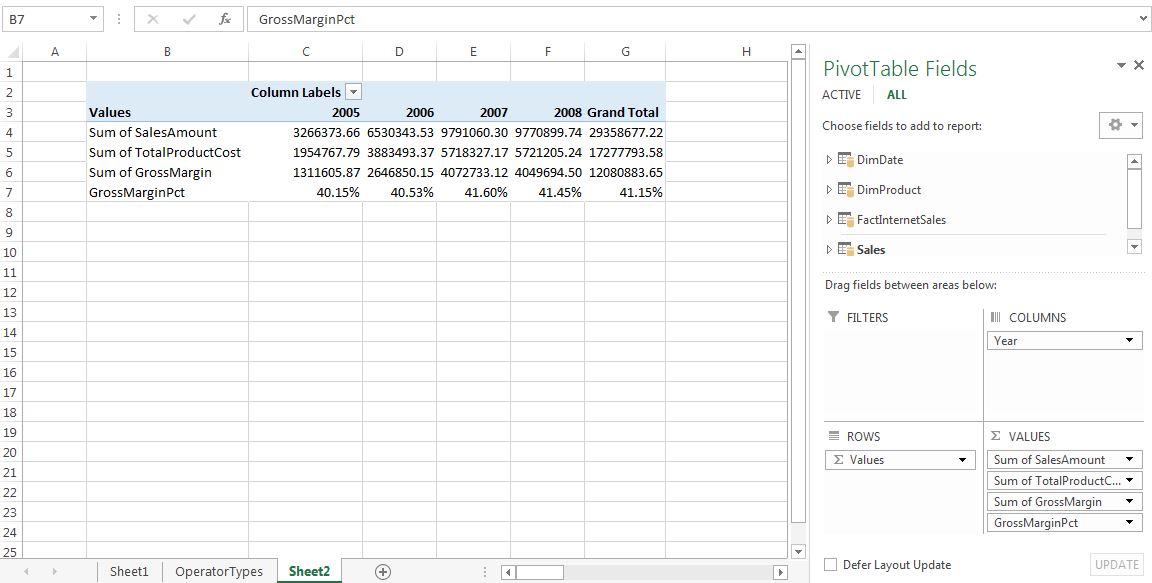
Wait! The GrossMarginPct numbers look quite large and not right at all. In fact, the formula took the summation of all the percentages and displayed the sum, which is not what we wanted (this is the incorrect way to formulate this GrossMarginPct calculated field.) We can remove the GrossMarginPct from the PivotTable.
The correct way to obtain the GrossMargin percentage as a calculated field is to click on the Calculated Fields button in the PowerPivot tab.
 |
| Fig. 10: Calculated Fields Button |
Name the new field GrossMargin%, and for the formula, type in:
=SUM(FactInternetSales[GrossMargin]) / SUM(FactInternetSales[SalesAmount])
as shown down below.
 |
| Fig. 11: Creating the GrossMargin% Field |
The syntax for the calculated field is similar to the calculated column formula; it just has an additional SUM function. This will be explained in later posts describing the DAX language. In the window, we are given options at the bottom to format the output of the calculation, and since it is a percentage, select the Percentage format. After we click OK, the calculated field, GrossMargin%, is added to the data model and is available to complete the PivotTable. Select it and confirm that it is in the Values area.
 |
| Fig. 12: Revised PivotTable with GrossMargin% |
Now these percentages look much more reasonable than the previous gross margin calculation, because it took the aggregate of the SalesAmount and the TotalProductionCost. We take a deeper look at calculated columns and fields later in P3.2.
Note:
The calculated field will be available to the PivotTable or report that we create using the data model. Think of it like this: we are building a data model, not just a report. The data model can be used for many other different reports or PivotTables, so as we transition into a good data modeler, we become better report creators.
Thanks for reading,
Wayne